
The entire desire to do this came about from reading about building a Stratum 1 clock using a Raspberry PI at http://www.satsignal.eu/ntp/Raspberry-Pi-NTP.html and from the use of a Sony radio clock to provide WWVB pulses from the WWVB receiver module that was used in the radio clock.
However, all of the projects and examples I found used Linux which I did not really want to use. I much preferred to use NetBSD, but it lacked a number of critical features that would be required to make a properly working Stratum 1 clock. Interrupt support for the GPIO pins was needed and adding a PPSAPI driver that could be triggered by a GPIO interrupt would be necessary.
The initial effort towards making a working Stratum 1 clock with PPSAPI was submitted as kern-51676. As of this writing the enhancement has not been reviewed and further changes have been made to improve upon the initial effort. In order to bring the story up to date, the following changes were made to the NetBSD source tree:
Three clocks have been built. Clock #1 is a GPS clock with PPSAPI support that mirrors in most ways the one found at Satsignal.eu. Clock #2 uses a WWVB receiver module to receive pulses from the WWVB VLF signal originating from Fort Collins, Colorado. The pulses are decoded with a modified radioclkd2 and fed to ntpd. Also, a PPSAPI source is provided that is also used by ntpd. Clock #3 is also a GPS based clock but uses a different GPS chip and different Raspberry PI model than Clock #1.
The first clock that was built uses a GPS module to acquire the rough time from the GPS satellite signals and then adds a PPS source to get an accurate second.
The hardware consists of:

Sparkfun has a PDF of the binary messages used by the Venus GPS module. It will need to be consulted to find out the commands that are to be sent.
The GPIO pins are configured as such:
gpio0 24 set in gpio0 26 set in gpio0 attach gpiopps 24 0x05 0x00 gpio0 27 set inGPIO pin 24 and 26 is the PPS source from the Venus GPS module. They are duplicated so that the gpiopps driver can use an interrupt on the rising edge and the falling edge, thus giving the ability to detect the both the assert and clear with PPSAPI. The ATOM driver in ntpd really only needs one edge to function correctly, so it is a bit redundant to provide both. GPIO pin 27 is tied to the NAV ready signal from the Venus module is used to determine if the Venus module has found enough satellites when the system is booting up. It may have been possible to read the PPS source pins for this purpose, but that pulse is quite short and it is possible that it might be missed by the perl code while the NAV signal is quite long and simple to detect if it is coming on and going off.
The following was placed into /etc/rc.conf:
venusgps=YES venusready=YES venusready_flags="--gpio gpio0 --pin 27" #Use default, GGA+10Hz+115200 venusgps_flags="--device /dev/dtyU0 --send_command --find-baudrate" clocksched=YESIt was found that using $GPGGA sentences at 115200 with a 10Hz update provided the most stable output from the Venus module and did not overburden ntpd. 20Hz was also tried but it caused strange jitter behavior probably due to over running a buffer somewhere. Also the slower update rates were also looked at and they did not perform as well as 10Hz. Likewise the default 1Hz update rate was tried with 115200 baud and it did not yield a significant amount of additional stability.
The /etc/ntp.conf was configured with the following lines:
server 127.127.20.0 mode 65618 minpoll 3 maxpoll 3 prefer fudge 127.127.20.0 time1 0.0 time2 0.060767 flag1 0 flag2 0 flag3 1 refid GPS server 127.127.22.0 minpoll 3 maxpoll 3 prefer fudge 127.127.22.0 flag3 1 refid PPSThe NEMA reference clock driver can leverage the PPSAPI source on its own, however, I found that was not stable, so what was settled upon was using the NEMA clock for the rough time and the ATOM reference clock for the precise second.
Tearing apart the Lacross showed the this:
To test for this I needed a oscilloscope and chose to get one of the inexpensive DSO138 kits that are sold on Amazon.
A word of warning... I purchased the DSO138 kit fully assembled from a vendor on Amazon. However, I did not know until I received the kit that it was actually counterfeit. The scope works just fine, but it is probably best to avoid counterfeit items on Amazon for any number of reasons.
Once the scope was hooked up to the suspected lines of the Lacross clock and power was applied to the clock, I was unable to find a signal that matched anything that I had found out about the WWVB modules. It is entirely possible that the Lacross used such a module and that the clock had been damaged enough from the battery leaking that it would not function, or it is possible that the module does not act like the other modules or that the lines I found are not the right ones.
In any case, I ended up using a WWVB receiver module from Universal-Solder eBay or the main site.
The hardware for the WWVB clock therefore consists of:
An attempt was made to put a DS1307 inside the enclosure with the WWVB receiver module. However, the DS1307 generated too much RF noise. A DS3231 was also tried, but its use caused problems. The DS3231 is a more accurate RTC which also features a temperature sensor. Something in the way NetBSD accesses the device caused a lot of excessive drift and jitter when trying to process the pulses from the WWVB radio module.
This is the RPI0, temperature sensor and the DS1307 chip:

This is the WWVB receiver module and its power supply. This is connected to the box with the RPI0 in it by a piece of CAT6 twisted pair.

To make use of the WWVB module, there has to be something that can read and process the pulses coming from it. There are two known programs that decode pulses from the VLF time sources that exist around the world, radioclkd and radioclkd2. The later is able to use PPSAPI to get the pulse width and has a couple of forks, one of which adds Linux GPIO support and fixed some bugs with the WWVB handling and these later fixes were of interest to me. I chose to leverage this fork and made it into a pkgsrc package to read the signals from the clock module. The patches contained in the package provide some minor fixes to the code and adds support for adjusting the tolerance around the pulse width. The default in the code of 0.04 was not wide enough for the module I used or for typical atmospheric conditions between me and Fort Collins where the WWVB transmitter is. A bug was fixed, or at least mostly fixed, in the code where the wrong date would be sent to ntpd at the roll over of midnight UTC. This complaint would happen every day:
Mar 10 19:00:01 clock2 ntpd[11586]: SHM: stale/bad receive time, delay=86401s Mar 9 19:00:01 clock2 ntpd[11586]: SHM: stale/bad receive time, delay=86401s Mar 8 19:00:01 clock2 ntpd[11586]: SHM: stale/bad receive time, delay=86401s Mar 6 19:00:01 clock2 ntpd[13649]: SHM: stale/bad receive time, delay=86401s Mar 5 19:00:01 clock2 ntpd[13649]: SHM: stale/bad receive time, delay=86401sAt 19:00:00 radioclkd2 should have reported 2017-070 00:00, that is midnight UTC is a new day, not 2017-069 00:00 which is midnight UTC for the previous day. A compensation was put into the code to increment mday when minute and hour were 00:00. This likely leaves a hole for the end of the year, but fixes it for the common case.
Mar 10 18:59:00 clock2 radioclkd2: WWVB time: 2017-069 23:59 Mar 10 18:59:00 clock2 radioclkd2: clock: radio time 1489190340.000000, average pctime 1489190340.058869, error +-0.008878 Mar 10 18:59:00 clock2 radioclkd2: shm: storing time 1489190340.000000 local 1489190340.058869 err 0.008878 leap 0 Mar 10 19:00:00 clock2 radioclkd2: WWVB time: 2017-069 00:00 Mar 10 19:00:00 clock2 radioclkd2: clock: radio time 1489104000.000000, average pctime 1489104000.059128, error +-0.009615 Mar 10 19:00:00 clock2 radioclkd2: shm: storing time 1489104000.000000 local 1489104000.059128 err 0.009615 leap 0 Mar 10 19:00:01 clock2 ntpd[11586]: SHM: stale/bad receive time, delay=86401s Mar 10 19:01:00 clock2 radioclkd2: WWVB time: 2017-070 00:01 Mar 10 19:01:00 clock2 radioclkd2: clock: radio time 1489190460.000000, pc time 1489190460.075434 Mar 10 19:01:00 clock2 radioclkd2: shm: storing time 1489190460.000000 local 1489190460.075434 err 0.005000 leap 0
Like the GPS clock a number of helper scripts were written for the WWVB clock:
The GPIO pins are configured as such:
gpio0 26 set out gpio0 26 1 gpio0 20 set in gpio0 21 set in gpio0 attach gpiopps 20 0x03 0x00 gpio0 17 set in gpio0 attach gpiopps 17 0x01 0x00GPIO pin 26 is tied to the enable pin on the WWVB module. An active low on this pin will enable the module while a high will disable it. Pins 20 and 21 is the pulse signal from the module and these are used by gpiopps to detect the assert and clear edges in radioclkd2. Both the assert and clear edges are required to allow radioclkd2 to measure the width of the pulse. Pin 17 is also the pulse signal and is fed to another instance of gpiopps to provide PPS input to ntpd.
wwvbenable=YES wwvbenable_flags="gpio0 26 0" wwvbready=YES wwvbready_flags="--gpio gpio0 --pin 20" radioclkd2=YES radioclkd2_flags="-s timepps -t wwvb -L 0.07 -H 0.07 -v /dev/gpiopps0:-dcd" clocksched=YES
Please note that the -L and -H arguments to radioclkd2 was added by my patches to allow for more tolerance in the pulse width. It was also noted that radioclkd2 would not decode the pulses unless it was told that they were reversed and it is unexplained as to why this is required. The clocksched rc.d file knows how to set the scheduler to be real time for both ntpd and radioclkd2 and was used to give the highest priority possible to radioclkd2 and ntpd.
machdep.cpu.frequency.target = 700This resulted in a very stable clock arrangement, more so than the previous 7.99.56 kernel and previous firmware, with only a modest offset from Clock #1 and Clock #3 and the rest of the world.
It should also be mentioned that running the RPI0 at a lower CPU clock rate also caused it to run considerably cooler, so it is also very possible that the SOC is more unstable at the higher CPU speeds due to temperature problems. The temperature reduction of a RPI3 running at a reduced clock was not nearly as big.
The hardware consists of:
The HAT comes with a bit of EEPROM that I fiddled with a bit, but was never able to get presented to NetBSD without locking up the I2C bus it was on. The EEPROM is suppose to be used to auto configure the HAT, but I really was not interested in how the device wanted to be auto configured. The EEPROM appears to be 4k long and the write pin is tied in such a manor as to make it read only, but that should be easy to change if one wanted to.
The DS3231 comes with a build in sensor for temperature that is presented to NetBSD just like any other sensor of that sort.

Adafruit has a set of PDFs that will provide the command and optional arguments used by the module. This will have to be consulted in order to know what the commands mean.
The GPIO pins are configured as such:
gpio0 21 set in gpio0 attach gpiopps 21 0x01 0x00GPIO pin 21 is the PPS source from the GlobalTop GPS module. There is no particular need to provide the clear PPSAPI signal as the ntpd ATOM driver only uses one pulse edge. As mentioned, the PPS pulse width of the GlobalTop GPS module is wide enough to sample directly to see if the module is alive and has acquired enough satellites.
The following was placed into /etc/rc.conf:
gtopgps=YES venusready=YES venusready_flags="--gpio gpio0 --pin 21" #Use GGA+5Hz+115200, disable logging disable backup / standby mode gtopgps_flags="--device /dev/dtyU0 --find-baudrate --send-command --command 251,115200 --command 314,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 --command 185,0 --command 225,0 --command 220,200" clocksched=YES
It should be noted that the GlobalTop module supports the $GPZDA sentence, but the documentation does not mention that. I could enable it with the command 314,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0. There also appears to be some support for the logging sentences and in fact Adafruit appears to sell a logger that is based upon this chip and I suspect uses these sentences.
Not as much experimentation has been performed with respect to the best NEMA sentences to use and the best rate to use them. What has driven experimentation is the issue mentioned later with respect to the likely firmware crashes. I ended up settling upon the $GPGGA sentence at 115200 with a 5Hz update rate. 10Hz was also tried and either appear to work pretty much the same as was the use of the $GPZDA sentence which also did not provide anything additional. It was noted that the default of 9600 baud proved to be less stable.
The /etc/ntp.conf was configured with the following lines:
server 127.127.20.0 mode 65618 minpoll 3 maxpoll 3 prefer fudge 127.127.20.0 time1 0.0 time2 0.90 flag1 0 flag2 0 flag3 1 refid GPS server 127.127.22.0 minpoll 3 maxpoll 3 prefer fudge 127.127.22.0 flag3 1 refid PPS
Another way to look at it is the check some of the numbers coming back from ntpd:
anduin% ntpq treebeard ntpq> rv 0 associd=0 status=0148 leap_none, sync_pps, 4 events, no_sys_peer, version="ntpd 4.2.8p9-o Mon Nov 21 20:53:18 EST 2016 (import)", processor="evbarm", system="NetBSD/7.99.56", leap=00, stratum=1, precision=-19, rootdelay=0.000, rootdisp=1.030, refid=PPS, reftime=dc694784.9e9f3805 Tue, Mar 7 2017 9:51:48.619, clock=dc694787.1190885f Tue, Mar 7 2017 9:51:51.068, peer=50631, tc=3, mintc=3, offset=-0.000853, frequency=-4.562, sys_jitter=0.001907, clk_jitter=0.002, clk_wander=0.001, tai=37, leapsec=201701010000, expire=201706280000 ntpq> ^D anduin%From samples taken every minute, it has been noted that the sys_jitter is nearly constant at 0.001907 and clk_jitter and clk_wander nearly always the numbers above +-0.001. The rootdisp is also quite low. The only comment one might make is the precision which is -19, or 2^-19, which is quite good, I think.
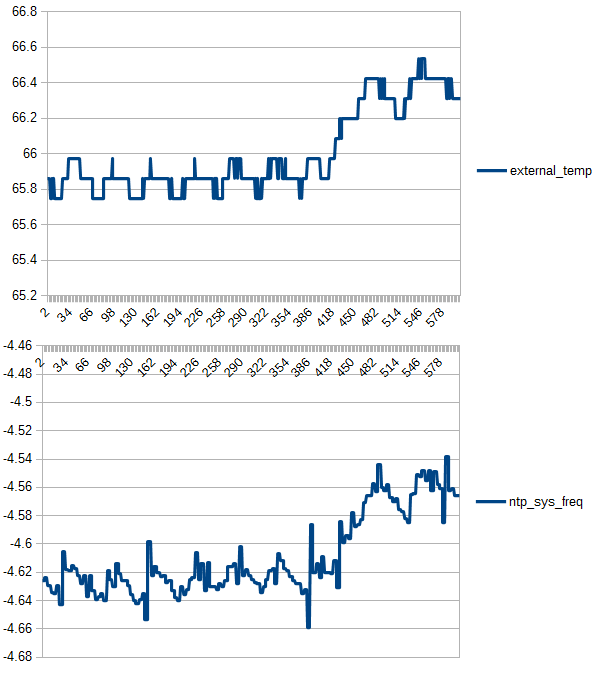
The heat in the room came on at the time when the frequency started to drop. Apparently the clock likes to be warm.
A second temperature related issue is that the CPU temperature goes go up in the RPI2 as it does more work. Adding the clearing edge, and changing the process scheduling of ntpd caused a couple of degrees of increased CPU temperature. This has not proved to be a problem in the cooler months, but we shall see it is becomes a problem later. The temperature of the CPU runs around 102 or 103 degrees F all of the time.
It has also been observed that Clock #1 will sometimes prefer his peer, Clock #2 for the rough time. This situation is not fatal, as it does not last for very long. The only odd side effect is that if another system is pooling for time at the instant this is happening it will find that the stratum level of Clock #1 has changed and probably note some differences in the clock metrics.
Clock #1 is also effected when heavy access occurs to the SDCARD. These graphs illustrate some of the effect. The two spikes occurred when the daily cronjobs that run by default in NetBSD were executed.
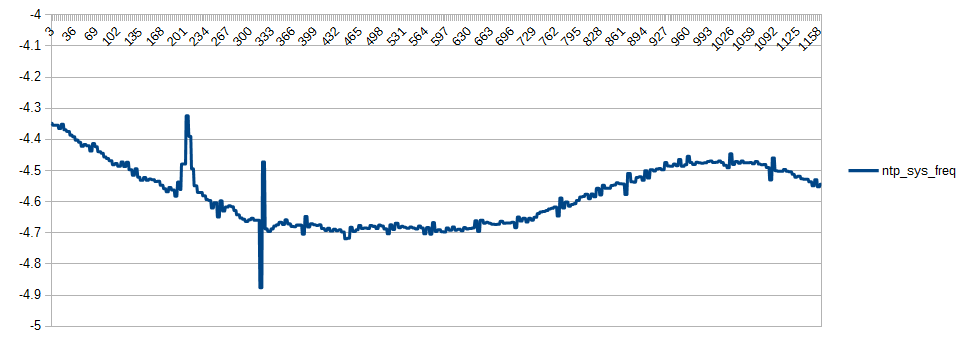
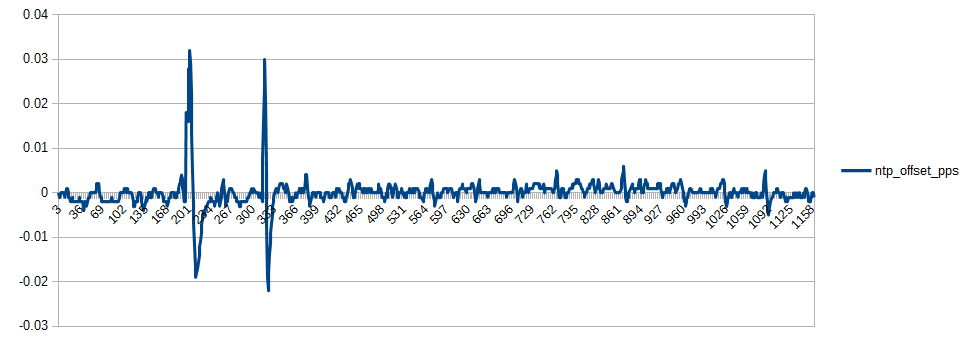
This spiking behavior was much worse when the process scheduling was not set to real time, but can not be eliminated completely. Note that the second graph illustrates a read via the PPSAPI, and hence is not related to the USB serial interface.
Looking at ntpd numbers one gets the following:
anduin% ntpq arnor ntpq> rv 0 associd=0 status=0115 leap_none, sync_pps, 1 event, clock_sync, version="ntpd 4.2.8p9-o Mon Nov 21 20:53:18 EST 2016 (import)", processor="evbarm", system="NetBSD/7.99.56", leap=00, stratum=1, precision=-18, rootdelay=0.000, rootdisp=37.902, refid=PPS, reftime=dc6948e4.98156195 Tue, Mar 7 2017 9:57:40.594, clock=dc6948fb.d2747b54 Tue, Mar 7 2017 9:58:03.822, peer=46861, tc=6, mintc=3, offset=5.378296, frequency=-2.671, sys_jitter=5.252032, clk_jitter=6.334, clk_wander=0.019, tai=37, leapsec=201701010000, expire=201706280000 ntpq> ^D anduin%After the upgrade to 8.99.3 this is what the stats look like when the signal from WWVB is good:
anduin% ntpq arnor ntpq> rv 0 associd=0 status=0115 leap_none, sync_pps, 1 event, clock_sync, version="ntpd 4.2.8p10-o Thu Apr 13 16:14:38 EDT 2017 (import)", processor="evbarm", system="NetBSD/8.99.3", leap=00, stratum=1, precision=-18, rootdelay=0.000, rootdisp=2.880, refid=PPS, reftime=dd9d9693.7b1bf28c Fri, Oct 27 2017 7:27:15.480, clock=dd9d96c7.bd7b16b9 Fri, Oct 27 2017 7:28:07.740, peer=6079, tc=6, mintc=3, offset=-0.202665, frequency=-2.750, sys_jitter=0.664578, clk_jitter=1.246, clk_wander=0.003, tai=37, leapsec=201701010000, expire=201712280000 ntpq> ^DI also capture samples every minute from this clock and note that the sys_jitter ranges all over the place. On this particular day, it ranged from 0.3139 to 16.1240. The other counts, clk_jitter, clk_wanter and rootdisp also wander around. The precision is noted as -18, or 2^-18. This is not awful, but also not as good as the GPS based clock. It is also entirely possible that the situation would improve by using something other than a RPI0.
From the point of view of another system in the enviroment, call it stratum_2_d, these are the peer numbers:
remote refid st t when poll reach delay offset jitter
==============================================================================
*clock_1 .PPS. 1 u 42 128 377 0.626 -0.122 0.042
+clock_2 .PPS. 1 u 116 128 377 0.869 0.397 1.055
+clock_3 .PPS. 1 u 123 128 377 0.537 -0.157 0.028
-stratum_2_a points_clock_1 2 u 28 128 377 0.331 -0.236 0.079
-stratum_2_b points_clock_1 2 u 26 128 377 0.272 -0.131 0.074
-stratum_2_c points_clock_1 2 u 111 128 377 0.800 1.945 0.122
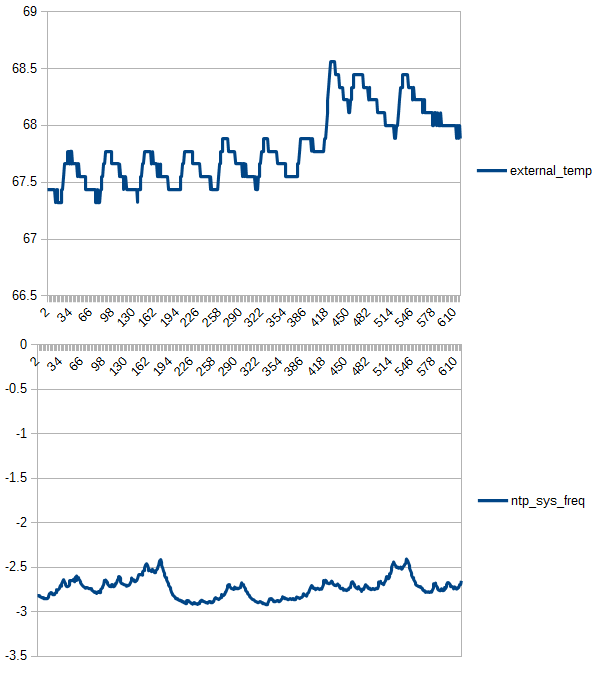
Further the CPU temperature stays around 96 or 97 degrees F. The thermal mass of the RPI0 is much smaller than the RPI2 and it is not enclosed in a case, which might be a factor. However, it is unclear in the GPS case if the temperature change is due to the RPI2 warming up or the GPS module.
The recovery of the pulse when the signal is less then perfect with radioclkd2. While there is a bit of recovery code in radioclkd2 it can not recover from what I call the "brief dropout".
On the oscilloscope this looks something like this:
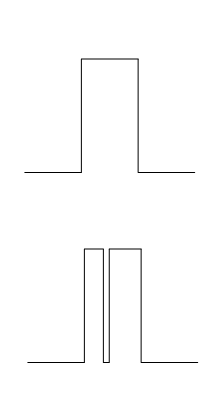
The top is what a pulse should look like, the bottom has experienced a drop out. What this looks like to PPSAPI is another pulse and this has a tendency to confuse radioclkd2. Signal reception is very bad if there is bad weather anywhere near my location, with near meaning anything within a large number of states around my location. There also tends to be a lost minutes in the afternoon, but if it was a good day for the WWVB signal, then this really isn't much of a problem. It also also been observed that it is possible to lose the rough date and time decoding, but still have fairly good second decoding. This results in Clock #2 getting it rough time from its buddy, Clock #1, and the seconds from the PPS signal.
An attempt was made to implement a WWVB decoder in perl with the goal of being able to add better pulse reconstruction, but it proved to be too slow. Further the lack of any sort of direct support for PPSAPI natively in perl made it hard to use. As a test it would work on static files that contained the pulse information from PPSAPI, but could not sample the pulses fast enough to make it workable when attached to a real live source. This effort will probably be revisited when I have more time.
A second issue was that ntpd appears to crash once in a great while. This was dealt with, crudely, by having a cron job run from time to time to make sure that ntpd is actually running and restart it if it is not running. It appears, on the surface of things, that ntpd quits more often if radioclkd2 is having trouble decoding time. If ntpd restarts and radioclkd2 has not acquired good time there is every chance that time keeping will become unstable. Most of the time, Clock #2 will recover from a restart of ntpd with bad receive conditions if good pulses and decodes are provided. However, it was noted that sometimes the ATOM driver will not manage recovery and ntpd had to restarted.
There may also be an issue with radioclkd2 if it has been running for a while. It has been noted that while it was able to decode the pulses, the PPS offset in ntpd was wildly outside of its normal values. Stopping and starting raidclkd2 dealt with the problem and this was included in the crude cron job check for ntpd mentioned above.
Unlike Clock #1, Clock #2 does not appear to suffer when the SDCARD is accessed during the daily cronjob. Indeed aside from a spike in CPU temperature, there appears to be nothing unusual about running the daily cronjob.
The ntpd service on Clock #2 will occasionally complain about stale SHM data. This especially happens when radioclkd2 has has trouble decoding the pulses and has not written one for a while.
The ntpd numbers are as follows:
mithlond% ntpq ntpq> rv 0 associd=0 status=011d leap_none, sync_pps, 1 event, kern, version="ntpd 4.2.8p9-o Mon Nov 21 20:53:18 EST 2016 (import)", processor="evbarm", system="NetBSD/7.99.56", leap=00, stratum=1, precision=-19, rootdelay=0.000, rootdisp=1.030, refid=PPS, reftime=dc7d89d2.97889e6d Wed, Mar 22 2017 19:40:02.591, clock=dc7d89d5.922ee18a Wed, Mar 22 2017 19:40:05.571, peer=21006, tc=3, mintc=3, offset=-0.003270, frequency=-8.573, sys_jitter=0.001907, clk_jitter=0.002, clk_wander=0.004, tai=37, leapsec=201701010000, expire=201706280000
57832 45619.694 127.127.20.0 $GPGGA,124019.500,4005.4137,N,08246.8895,W,2,08,1.12,335.5,M,-33.2,M,0000,0000*56 79 79 0 0 0 0 57832 45627.694 127.127.20.0 $GPGGA,124027.600,4005.4138,N,08246.8894,W,2,08,1.10,335.8,M,-33.2,M,0000,0000*59 81 81 0 0 0 0 57832 45635.694 127.127.20.0 $GPGGA,124035.600,4005.4139,N,08246.8895,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*54 80 80 0 0 0 0 [The module stops sending anything down the serial port] 57832 45643.695 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 43 43 0 0 0 0 57832 45651.695 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 45659.695 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 45667.696 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 45675.696 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 45683.696 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 . . . 57832 47475.695 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 47483.695 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 47491.695 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 57832 47499.696 127.127.20.0 $GPGGA,124039.900,4005.4140,N,08246.8893,W,2,08,1.10,335.6,M,-33.2,M,0000,0000*5F 0 0 0 0 0 0 [The module was reset here and ntpd restarted] 57832 47671.498 127.127.20.0 $GPGGA,131431.400,4005.4088,N,08246.8879,W,1,09,1.04,330.6,M,-33.2,M,,*59 10 10 0 0 0 0 57832 47679.501 127.127.20.0 $GPGGA,131439.400,4005.4087,N,08246.8882,W,1,09,1.04,330.6,M,-33.2,M,,*5A 80 80 0 0 0 0 57832 47687.502 127.127.20.0 $GPGGA,131447.400,4005.4087,N,08246.8881,W,1,09,1.16,330.6,M,-33.2,M,,*53 80 80 0 0 0 0 57832 47695.502 127.127.20.0 $GPGGA,131455.400,4005.4088,N,08246.8881,W,1,09,1.16,330.6,M,-33.2,M,,*5F 80 80 0 0 0 0 57832 47703.501 127.127.20.0 $GPGGA,131503.400,4005.4092,N,08246.8882,W,1,09,1.16,330.6,M,-33.2,M,,*55 80 80 0 0 0 0 57832 47711.501 127.127.20.0 $GPGGA,131511.400,4005.4099,N,08246.8882,W,1,09,1.16,330.7,M,-33.2,M,,*5C 80 80 0 0 0 0
I ended up writing a perl script that detects when this condition occurs and kicks the GPS module in that case.
The original module used in Clock #3 is believed to be a MTK3333. This module, as mentioned, would seem to "crash" and stop proving updates. It was later noted that this was likely a complete reset due to the fact that the baud rate reverted back to 9600 baud. The module in Clock #3 was replaced with a MTK3339 / PA1616S which mostly uses the same configuration. It will hopefully be more stable and not have a tendency to "crash" and "reset".